
The Hidden Threat to Experiment Validity - Contamination in A/B Testing
When Assigned Groups Don’t Match Real-World Exposure - Understanding and Preventing Contamination in A/B Testing

Introduction
Imagine running an A/B test where your winning variant should boost revenue by 10% - but the final report shows almost no lift. You double-check the math, the p-value looks fine, and your sample size is solid. The culprit? Contamination - users meant for one group sneak a peek at the other.
When we think of running a successful A/B test, the spotlight often falls on statistical rigor:
Do we have enough samples to reach statistical significance?
How long should we run the test to avoid early stopping bias?
Are our confidence intervals tight enough for decision-making?
While these questions are critical and often take center stage, the foundation of any trustworthy experiment is built much earlier - during the design stage - by clearly defining and fully isolating treatment and control samples.
The primary assumption of randomized controlled experiments is that the samples in control and treatment are both:
Identical in distribution before the test starts (exchangeable), and
Independent in exposure throughout the test duration.
Violating these assumptions undermines the entire experiment. The most common - yet often overlooked - violation is contamination, where units assigned to one variant are inadvertently exposed to elements of another variant’s experience.
While contamination may seem similar to interference or network effects (where the treatment received by one unit affects the outcomes of other units), they are conceptually distinct.
Contamination is about direct cross-exposure - users “switching sides” or seeing both versions - whereas interference refers to indirect influence, such as word-of-mouth or shared resources that spread treatment effects beyond the intended group. Both can bias results, but contamination is typically more controllable through assignment and tracking design.
And here’s the reality: contamination is far from rare. In mature experimentation programs, it’s often silently eroding effect sizes. Meta, Microsoft, and Booking.com have reported that unaddressed contamination can reduce measured lift by 30–70% in severe cases (Kohavi et al., 2009).
In this post, we’ll unpack :
What “contamination” really means in A/B testing.
Walk through real-world examples of how it sneaks into experiments.
Show how big the impact can be, with numbers from industry benchmarks.
Share simple setup tips to stop contamination before it starts.
Cover a few statistical tricks to clean up results if contamination happens.
What “Contamination” Really Means in A/B Testing
In a well-designed A/B test, Control (A) and Treatment (B) groups are like parallel worlds - completely separate, with no overlap in user experience. This separation is what lets us say, “Any difference in results came from the change we made, not from anything else.”
Contamination is what happens when that wall between A and B cracks. It might be accidental (a user logs in on a different platform) or unavoidable (cookies get cleared, app gets reinstalled), but the result is the same: some users end up experiencing both variants.
The table below shows a real-world style example:
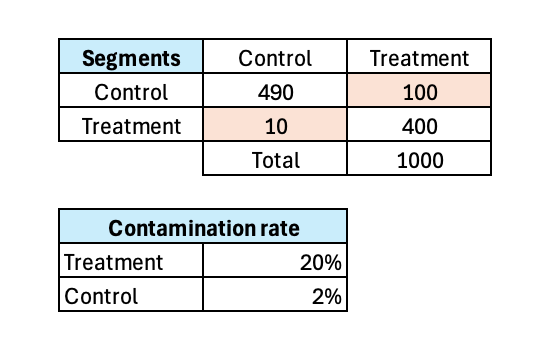
From this, we can calculate:
Treatment contamination rate: 20% (100/500) – meaning 1 in 5 users assigned to treatment actually saw the control experience at least once but not randomly.
Control contamination rate: 2% (10/500) – far lower, because the control experience is usually the default or “business as usual” state.
This asymmetry is common: contamination is typically higher on the treatment side because breaks in assignment often default the user back to control.
When contamination sneaks in, three big problems follow:
Breaks independence – Users influenced by both variants blur group differences.
Shrinks or flips lift – Groups drift toward each other, hiding real wins.
Hurts statistical power – Smaller measured differences mean more users and longer tests.
Real-World Contamination Examples
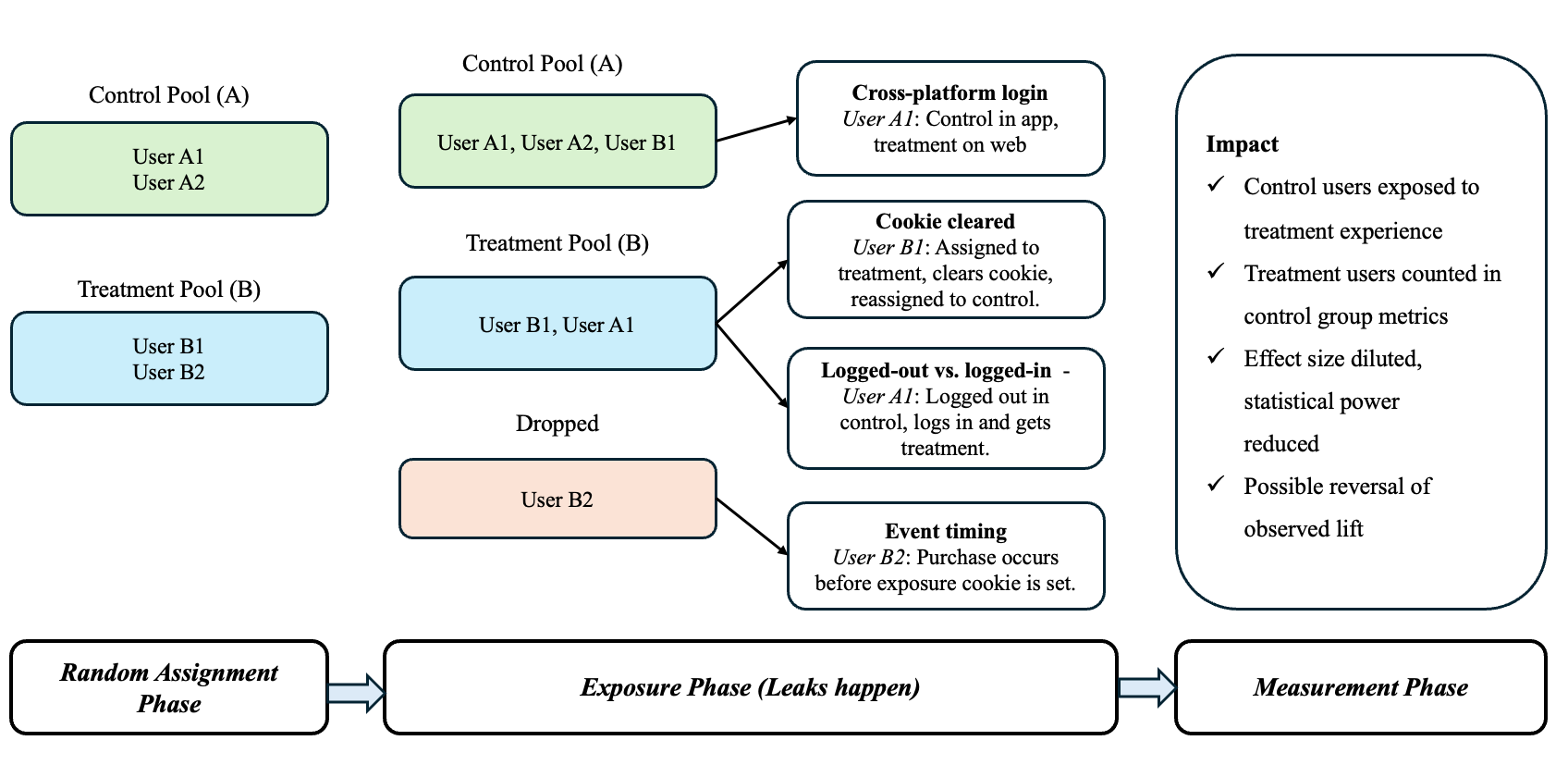
Mental model of contamination in A/B Testing
These are the most common leaks we see in mature experimentation programs:
Cross-platform activity
Example: User A1 is assigned to Control in the app, but logs into the web and gets Treatment.
Impact: User experience is mixed, so their actions reflect both versions.
Cookie or local storage loss
Example: User B1 is in Treatment, clears their browser cookie, switch to incognito mode, or reinstall an app and is reassigned to Control.
Impact: User is double-counted in metrics, blurring differences between groups.
Logged-out vs. logged-in state
Example: User A1 is Control while logged out, but logs in and gets Treatment.
Impact: Session-based tracking fails to keep assignments consistent across states.
Event timing misaligned
Example: User B2 purchases before the exposure cookie is set, so their action isn’t attributed correctly.
Impact: Key events fall outside the tracking window, making the test seem less effective.
Overlapping experiments
Example: User B2 is in a homepage layout test and a pricing experiment simultaneously, with one test unintentionally affecting the other’s metrics.
Impact: Results become confounded, making it unclear which change drove the observed effect.
How Big the Impact Can Be - Industry Benchmarks
Studies from large-scale experimentation platforms show how damaging unmitigated contamination can be:
Meta: Lift reductions of 30–50% in cross-platform scenarios.
Microsoft: Effect sizes diluted by up to 70% when assignment is not persistent across devices.
Booking.com: Even a 5–10% contamination rate can require double the sample size to reach the same significance level.
Before we dive into the next section on preventing contamination, feel free to subscribe below.
How to Prevent Contamination Before It Starts
The easiest contamination to fix is the kind that never happens. While no system is perfect, you can dramatically reduce leaks by tightening how you assign, sync, and persist your experiment groups - and by monitoring for cracks before they grow. Here’s how:
1. Assign at the right entity level
Make sure your randomization matches the way your metric is measured.
If your analysis is on users, assign at the user ID level.
If you’re testing something that spans devices or affects households (e.g., streaming subscriptions, shared accounts), assign at the household ID or device ID level to capture the full effect.
Example: For a logged-in Netflix test, use the account ID so all devices under that account see the same variant.
2. Synchronize assignment across platforms
Don’t let your mobile app, web app, and backend each decide assignment independently. One person could easily end up in control on mobile and treatment on desktop. Centralize assignment logic so the same user always gets the same bucket, no matter where they log in.
Example: Store assignments in a central service (e.g., experiment assignment API) and call it from all platforms.
3. Persist assignment beyond browser cookies
Browser cookies and local storage are fragile - users clear them, browsers expire them, and incognito sessions bypass them. Persist assignments in a server-side database keyed to the user ID (or another durable identifier).
Example: Even if a user uninstalls and reinstalls your app, the assignment can be restored from server-side storage.
4. Audit and monitor for leaks
Build logging that records both the assigned variant and the variant actually shown to the user. Then run daily checks for mismatches. This lets you detect contamination early - before it tanks your results.
Example: If you see that 20% of “treatment” users viewed control content in the past 24 hours, you can pause the test and fix the bug before continuing.
When Contamination Happens: How to Clean Up Your Results
Even with the best prevention, some contamination will slip through - users will clear cookies, log in from multiple devices, or hit incognito mode. The good news? You can still salvage your test by adjusting your analysis to reduce the bias.
Here are three statistical approaches used in industry to rescue contaminated experiments:
1. Instrumental Variables (IV) – Separate assignment from exposure
In contaminated experiments, assignment (what the randomizer said a user should see) often differs from exposure (what the user actually saw). For example, users might clear cookies, use multiple devices, or log in via incognito, causing crossovers between control and treatment.
The Instrumental Variables (IV) approach rescues such tests:
Instrument = Assignment (random by design, unaffected by user behavior).
Treatment = Exposure (possibly contaminated).
Because assignment is random, it is uncorrelated with hidden confounders. By isolating only the part of exposure explained by assignment, IV removes bias introduced by contamination.
Example: Crossovers in a Test
Setup: 500 assigned to Control, 500 to Treatment.
Contamination: 100 Control users actually saw Treatment (20%); 10 Treatment users actually saw Control (2%).
Exposure by assignment (the “first stage”):
P(D=1|Z=1)=490/500=0.98
P(D=1|Z=0)=100/500=0.20
First-stage difference: 0.98-0.20=0.78
Intention-to-Treat (ITT): The effect by assignment (diluted by crossovers).
If the true treatment effect is +5 pp (attenuated) and you observed ITT = 4.0 pp, that’s difference in expectation.
IV correction (Wald / 2SLS): Divide ITT by the first-stage
IV}=ITT/(P(D=1|Z=1) - P(D=1|Z=0)) =0.04/0.78 = 0.051 (close to 5.1%)
2. Exposure-Based Re-weighting – Adjust for “partial exposure”
Not all contamination is binary. Some users may see 80% control and 20% treatment experiences.
Track the fraction of exposures per user in each variant (e.g., page views, impressions, sessions).
Use these fractions as weights in your outcome analysis, so a “mostly control” user is counted more heavily toward the control group.
Example: If a logged-in user spends most of their time on mobile (control) but occasionally visits web (treatment), their contribution to the treatment group is proportionally reduced.
3. Post-Assignment Filtering – Only analyze “pure” users
Sometimes the simplest option is the most effective - just drop contaminated users from the analysis.
Keep only those whose observed variant matches their assigned variant for the entire test window.
The trade-off: You lose sample size, so your statistical power drops. But you gain cleaner, more trustworthy estimates.
Example: If 20% of users crossed over, removing them could restore the original 10% lift you expected - at the cost of needing a longer test to regain confidence.
Pro tip: Industry teams like Microsoft’s Experimentation Platform combine these approaches - filtering for the cleanest 80–90% of users, then applying IV on the rest to squeeze out every bit of signal without bias.
In the end, great experimentation programs aren’t just about picking the right p-value threshold or running the test for the “correct” duration - they’re about ensuring the integrity of the assignment. That foundation is what turns raw experiment data into reliable business decisions.
Subscribe for insightful content on all things product data science.
TL;DR of the blog
Contamination = users see both Control and Treatment, breaking isolation.
Different from interference - it’s direct cross-exposure, not indirect influence.
Usually higher on the Treatment side since Control is the default.
Even small contamination rates can shrink lift, flip results, and require bigger samples.
Common causes: cross-platform logins, cookie loss, login state changes, overlapping tests.
Prevent with proper assignment level, cross-platform sync, server-side persistence, and active monitoring.
If it happens: use Instrumental Variables, Exposure Re-weighting, or Post-Assignment Filtering.
Strong assignment design is the best defense for trustworthy A/B tests.
This was a really great read and a comprehensive guide as to how to handle these sort of problems.