
Where Does Product Data Science Live? Mapping Its True Place in the Data Science Universe
Understanding where the role sits in the data science world and why its influence is expanding fast.


The phrase “data science” often gets used as if it refers to one monolithic discipline. In reality, it is an ecosystem, a set of interconnected but distinct functions that transform raw data into business impact. Under this umbrella sit several specialties:
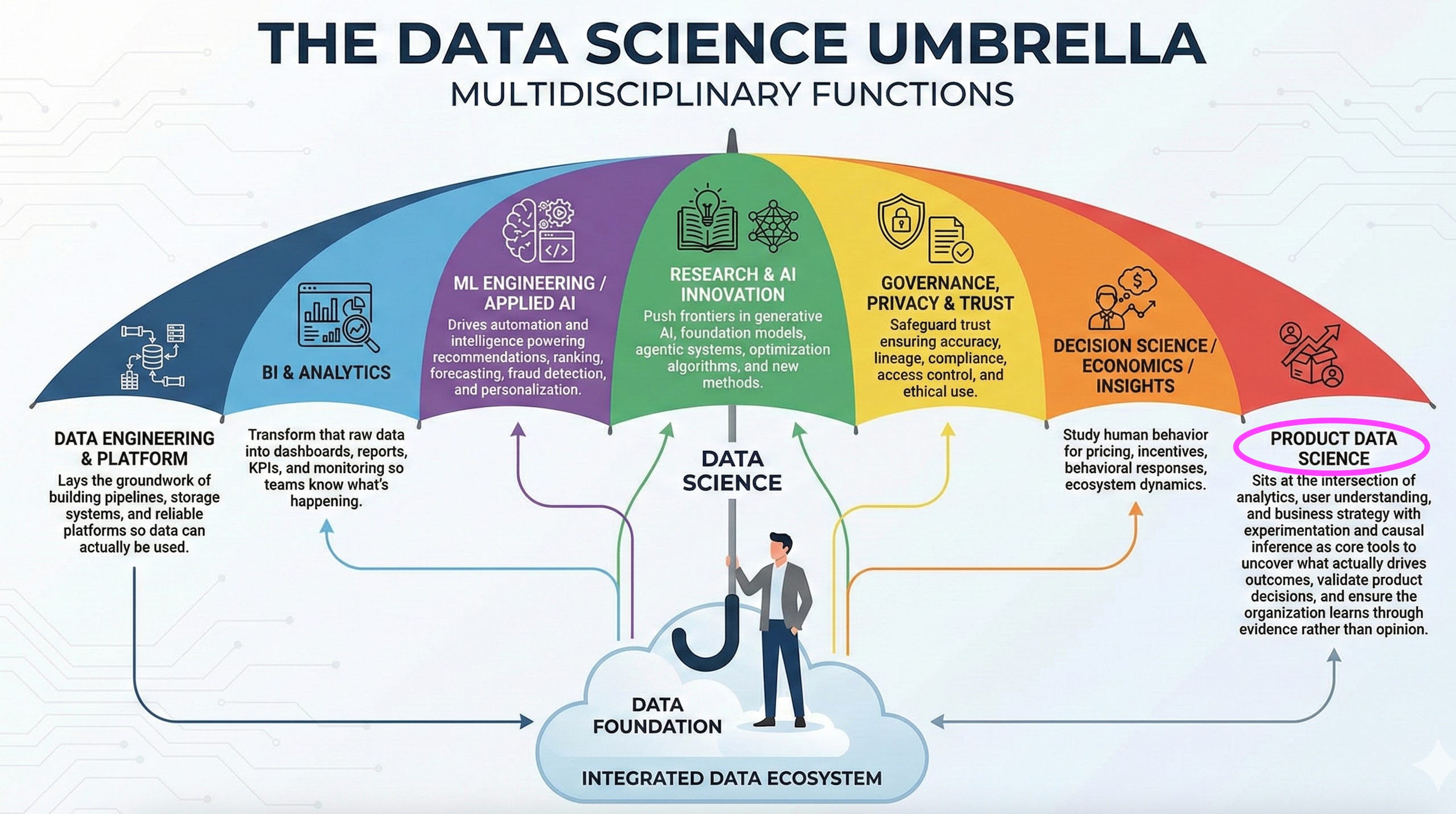
Data Engineering lays the groundwork of building pipelines, storage systems, and reliable platforms so data can actually be used.
BI & Analytics transform that raw data into dashboards, reports, KPIs, and monitoring so teams know what’s happening.
ML Engineering / Applied AI drives automation and intelligence powering recommendations, ranking, forecasting, fraud detection, and personalization.
Research & AI Innovation push frontiers in generative AI, foundation models, agentic systems, optimization algorithms, and new methods.
Governance, Privacy safeguard trust ensuring accuracy, lineage, compliance, access control, and ethical use.
Decision Science / Economics / Insights study human behavior for pricing, incentives, behavioral responses, ecosystem dynamics.
Product Data Science focuses on user behavior, and understanding business strategy with experimentation and causal inference as core tools to uncover what actually drives outcomes.
1. So Where Does Product Data Science Actually Live?
Product Data Science (PDS) lives at the intersection of several disciplines:
Product management: Forming hypotheses, evaluating trade-offs, and prioritizing bets
Behavioral economics: Understanding incentives, friction, and how users actually respond
Analytics: Defining metrics, segmenting customers, diagnosing funnels, and analyzing patterns
Experimentation & causal inference: Validating whether changes caused outcomes and why
Light modeling & decision systems: Identifying drift, thresholds, and opportunity areas
Questions that often come up include:
“Why is this called data science instead of analytics if you are not building models?”
It’s a fair question and one I’ve been asked many times. Here’s how I explain it.
Product Analytics explains what happened by reporting trends, diagnosing patterns, and giving visibility into performance.
Traditional ML / Applied Data Science builds models that predict what will happen next or automate decisions through ranking, recommendation, forecasting, or classification.
Product Data Science decides what we should do, using experimentation, causal inference, behavioral insight and drawing from both analytics and ML to shape product strategy and outcomes.
Here’s a side-by-side view:

Product Data Science sits squarely within Data Science - shaping what gets built, why it matters, and how success is validated
2. Where Does This Team Sit in the Org Structure?
Good placements include:
✔ Embedded within product teams, working closely with PMs, engineers, and UX
✔ A dotted-line connection to central data science leadership for standards, methods, and mentorship
What matters most is positioning. When the team is structurally far from product strategy, its insights often stay in presentations instead of influencing features or outcomes. Likewise, if it is viewed simply as the group that fetches metrics, its true capabilities in experimentation, causal inference, user reasoning, and decision influence rarely get used.
When set up thoughtfully, PDS becomes a learning and decision partner to product leadership.
3. What Qualifications & Skillsets Define a Strong Product Data Scientist?
A strong PDS profile blends:
Technical Rigor
Experiment design : Randomized Controlled Tests (A/B Testing), Quasi experimental designs like DiD, Matching, Synthetic Controls, Uplift modeling, Sensitivity analysis and statistical inference
Statistical Decision Frameworks: Confidence intervals, variance modeling, metric sensitivity, power analysis, lift decomposition.
Lightweight Machine Learning: Segmentation, risk scoring, propensity models, uplift models, and feature experimentation, not heavy architecture building, but applied ML tuned for product actionability.
Metric Architecture & Monitoring : Building driver trees, anomaly detection for metric monitoring, treatment effect hierarchies, guardrail structures, and behavioral telemetry i.e., knowing which numbers matter and why.
Data Access & Processing: Advanced SQL, data modeling, ETL familiarity, and proficiency with large-scale warehouse environments (Snowflake, BigQuery, Redshift, Databricks)
Product Sense
Hypothesis framing: What behavior should change, why would it change, and how much do we expect?
Economic & Behavioral Reasoning: Understanding user friction, incentive gradients, cannibalization dynamics, platform externalities, network effects.
Journey Decomposition: Breaking funnels, intent paths, conversion loops, and customer lifecycle events into measurable levers.
Cost–benefit/Trade-Off thinking: Balancing revenue vs. satisfaction, precision vs. coverage, short-term conversion vs. long-term loyalty.
Communication & Influence
Narrative Framing & Storytelling: Turning noisy findings into decisions executives can act on.
Influencing Without Authority: Driving alignment across PMs, designers, engineers, growth teams, finance, and leadership.
Experiment Interpretation & Decision Procedures: Translating statistical outcomes into roadmap calls for launch, iterate, kill, or re-test with rationale.
Being the Product Truth Function: Preventing feature launches that look good on a dashboard but fail in equilibrium reality.
All of the concepts discussed above are distilled in depth from an experimentation perspective in this playbook. It is currently available at a holiday price of $100 (down from $300).
4. What Does Career Growth Look Like in Product Data Science?
Career growth in Product Data Science is less about stacking technical skills and more about increasing ownership, influence, and the ability to drive business outcomes. The trajectory shifts from answering questions to shaping the questions themselves.
Rather than being evaluated only on coding or modeling depth, progression is anchored in:
Owning meaningful product and metric problems
Influencing product direction through data-backed recommendations
Designing experiments and defining success criteria
Anticipating business needs instead of reacting to them
Demonstrating measurable impact on growth, retention, or efficiency
A common path looks like:
Product Analyst → Product Data Scientist → Senior / Staff → Manager / Principal → Head of Product Data Science / Experimentation
As people advance, the role evolves from individual analysis to decision leadership. The strongest practitioners grow into:
Strategic partners to product leadership
Architects of testing and causal inference frameworks and measurement culture
Advisers shaping growth strategy, incentives, and portfolio bets
5. How Companies Are Evolving Their View of Product Data Science?
Over the past few years, Product Data Science has evolved from a support function into one of the most strategically influential roles in digital organizations. The shift is most visible in companies like OpenAI, Meta, Google, Walmart, where product data science and experimentation teams now operate at the same level as product, engineering, and growth rather than underneath them.
Startups are beginning to follow this trend too. Many now hire product data scientists even before machine learning specialists because early-stage success depends more on making the right decisions than on building advanced models.
Before automation, recommendation systems, or personalization matter, companies need to understand what to build, why, and whether it delivers value. That is the core charter of product data science.
AI-focused companies are expanding the scope further.As generative AI scales, organizations need truth-seeking systems that evaluate outcomes, detect when the model is wrong, and prevent hallucination-driven risks. Because Product Data Science already owns measurement and learning, it naturally becomes the function that closes the loop - turning live model errors, drift signals, and behavioral impacts into feedback for the AI/ML teams to refine models, improve safety, and optimize performance in production.
(For reference, below is a snapshot of open Product Data Science roles across top tech and AI first companies.)
If this sparked your curiosity, you’re in the right place. Follow and subscribe - we’ll dig into the experiments, decisions, models, and messy realities that make Product Data Science one of the coolest jobs in tech today.
 | A guest post by
|
Superbly articulated mapping of PDS in the datascience landscape. The distinction beween analytics (what happned), ML (what will happen), and PDS (what should we do) is powerful because it highlights a capability gap most companies don't recognize. The framing of PDS as a learning partner rather than a metrics team completely shifts the conversation around experimentation from validation tool to strategic decision function.
I have often found it difficult to get clear explanations from data professionals or professors about the differences between analytic data science, product data science, and marketing data science...etc., especially since the term ‘data science’ is used so broadly by recruiters and can be hard to get to speak and verify with hiring managers. I appreciate this article, and I will use it as one of the tools to help shape my career trajectory as a data science student