
Beyond A/B Testing: Part 3a - From Static Splits to Adaptive Learning with Multi-Armed Bandits
Why traditional A/B tests fail to adapt in real time, and how bandit algorithms reduce wasted traffic on underperforming variants


Welcome back to our series on pushing past the limitations of traditional A/B testing.
In Part 1, we explored Sequential Testing as a way to make faster, statistically sound decisions by peeking at test results in a controlled manner.
In Part 2, we took a deep dive into Interleaving, a faster, more sensitive approach for comparing ranking systems, particularly useful for experiences involving ranked lists or personalized content such as search results, product feeds, or movie recommendations.
Now, in Part 3, we turn to another major shortcoming of classic A/B testing: once you split traffic (e.g., 50/50), it doesn’t adapt in real time. This means that even when early results clearly show a variant underperforming, users may continue to see that subpar experience until the test concludes.
Enter Multi-Armed Bandits (MABs): a family of adaptive algorithms designed to dynamically allocate traffic toward better-performing options, reducing wasted exposure to losing variants while still balancing the need for exploration.
Why Do A/B Tests Struggle in Adaptive Scenarios?
Classic A/B tests assume a static split of traffic (e.g., 50/50 or 70/30). While this works for clean comparisons, it becomes a liability in dynamic, real-world environments:
Wasted exposure to bad variants - users keep seeing poor experiences, leading to opportunity cost in revenue, engagement, and satisfaction.
No mid-flight adaptation - A/B splits are rigid, unable to adjust as evidence accumulates.
Scaling challenges with multiple variants - traffic gets diluted in A/B/n tests, slowing down learning.
Slow, sometimes stale insights - you often need to wait until the full horizon, by which time behavior or conditions may have shifted.
User trust concerns - knowingly serving underperforming variants can harm trust in sensitive domains.
This is where adaptive methods like Multi-Armed Bandits (MABs) step in. Bandit algorithms dynamically reallocate traffic toward better-performing options, reducing wasted exposure, scaling gracefully to multiple variants, and providing timely insights while protecting user experience.
What is MAB ?
At its core, a Multi-Armed Bandit (MAB) balances two competing goals:
Exploration → trying different options to gather knowledge.
Exploitation → leaning into the best-performing option so far.
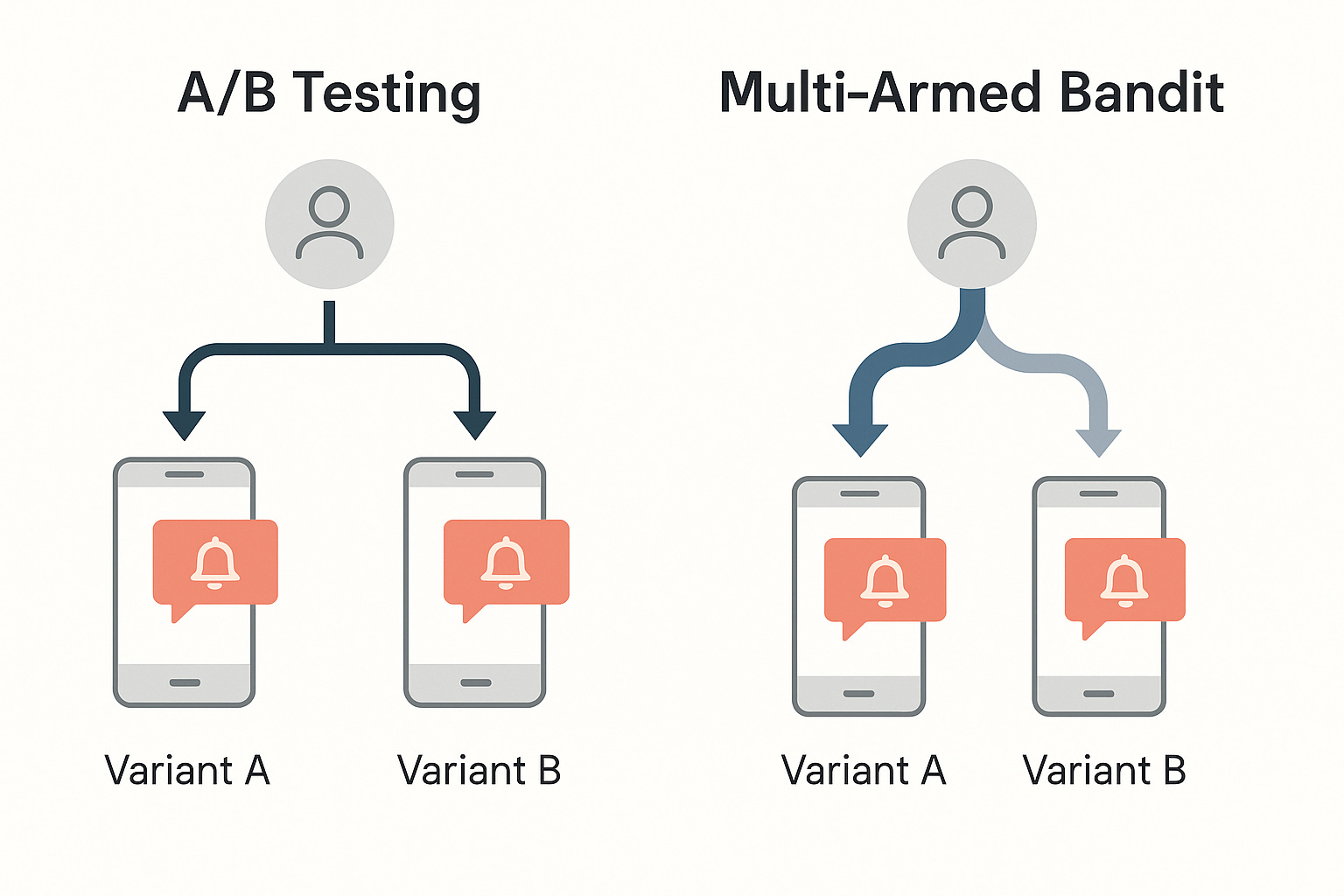
Example: App Notifications
A/B Testing: Half your users always get Notification A, and half always get Notification B, regardless of which one works better.
MAB: As soon as users start responding more to Notification A, the system automatically sends more traffic there, while still occasionally testing Notification B to confirm.
A Bit of History of MAB
The multi-armed bandit problem has its roots in probability theory and decision-making under uncertainty. The metaphor of slot machines (“one-armed bandits”) emerged in the 1930s, capturing the essence of balancing exploration vs. exploitation. From then, the field evolved in waves: early problem statements, theoretical foundations, practical algorithms, and modern applications in adaptive experimentation and AI.

Different Types of MAB and Industry Adoption
Multi-Armed Bandit algorithms span a spectrum of complexity - from simple heuristics like ε-Greedy, to mathematically grounded methods such as UCB, to Bayesian approaches like Thompson Sampling, and on to more advanced contextual and structured variants.
In practice, only a few have become dominant: Thompson Sampling is the most widely adopted across industry thanks to its strong empirical performance, ease of explanation, and scalability, while Contextual Bandits are increasingly powering personalization systems in feeds, recommendations, and e-commerce. More specialized algorithms, such as non-stationary and hierarchical bandits, are applied in dynamic or multi-level environments like surge pricing or ad campaign optimization but remain niche.
The key takeaway is that the “right” algorithm is less about sophistication and more about aligning the method to traffic scale, data richness, and business dynamics.

As a product data scientist or PM, you’re often faced with the question: which bandit algorithm should I use? With so many options out there, the decision can feel overwhelming. The diagram below lays out a step-by-step decision flow, guiding you through the key considerations so you can confidently match the right approach to your product’s needs.

Can MAB and A/B Testing Work Together or Should They Replace Each Other?
Now, when we position MAB as a test that can handle dozens of variants at once, even 50+, stakeholders often get excited. The promise of scaling experimentation effortlessly is compelling, but it’s easy to forget the real objective: not just testing more, but making better, faster decisions while preserving learning value.

Hope you enjoyed this blog! Don’t worry if some terms felt unclear or a bit cryptic-things will click in the next part, where we’ll cover:
Real-World Examples for MAB
Foundational Elements for Scaling MAB in Your Organization
How to Bring Stakeholders Along
Demonstrating the Value of MAB with Python Simulations
Subscribe to get notified when the next part drops.
 | A guest post by
|